


In this Article, we are going to learn about Distributed Systems. Here we are focusing on these things,
- What is Distributed Systems
- How does Distributed Systems work
- Why Distributed Systems
- Characteristic of Distributed Systems
- Challenges of Distributed Systems.
- Risks using Distributed Systems
- Distributed System Architecture & Types
- Distributed Data Stores(Cassandra)
- CAP Theorem
- Distributed Messaging
- Data Copying
- Decentralized vs Distributed Systems
- Cloud vs Distributed Systems
What is a distributed system?
A distributed system in its most simplest definition is a group of computers working together as to appear as a single computer to the end-user.
These machines have a shared state, operate concurrently and can fail independently without affecting the whole system’s uptime.
A distributed system is any network structure that consists of autonomous computers that are connected using a distribution middleware. Distributed systems facilitate sharing different resources and capabilities, to provide users with a single and integrated coherent network. The opposite of a distributed system is a centralized system. If all of the components of a computing system reside in one machine.
Unlike traditional databases, which are stored on a single machine, in a distributed system, a user must be able to communicate with any machine without knowing it is only one machine. Most applications today use some form of a distributed database and must account for their homogenous or heterogenous nature.
In a homogenous distributed database, each system shares a data model and database management system and data model. Generally, these are easier to manage by adding nodes. On the other hand, heterogeneous databases make it possible to have multiple data models or varied database management systems using gateways to translate data between nodes.
Distributed Information Systems: distribute information across different servers via multiple communication models.
Distributed Pervasive Systems: use embedded computer devices (i.e. ECG monitors, sensors, mobile devices).
Distributed Computing Systems: computers in a network communicate via message passing.
Distributed systems must have a shared network to connect its components, which could be connected using an IP address or even physical cables.
How does a distributed system work?
Distributed systems have evolved over time, but today’s most common implementations are largely designed to operate via the internet and, more specifically, the cloud. A distributed system begins with a task, such as rendering a video to create a finished product ready for release. The web application, or distributed applications, managing this task — like a video editor on a client computer — splits the job into pieces. In this simple example, the algorithm that gives one frame of the video to each of a dozen different computers (or nodes) to complete the rendering. Once the frame is complete, the managing application gives the node a new frame to work on. This process continues until the video is finished and all the pieces are put back together. A system like this doesn’t have to stop at just 12 nodes — the job may be distributed among hundreds or even thousands of nodes, turning a task that might have taken days for a single computer to complete into one that is finished in a matter of minutes.
There are many models and architectures of distributed systems in use today. Client-server systems, the most traditional and simple type of distributed system, involve a multitude of networked computers that interact with a central server for data storage, processing or other common goal. Cell phone networks are an advanced type of distributed system that share workloads among handsets, switching systems and internet-based devices. Peer-to-peer networks, in which workloads are distributed among hundreds or thousands of computers all running the same software, are another example of a distributed system architecture. The most common forms of distributed systems in the enterprise today are those that operate over the web, handing off workloads to dozens of cloud-based virtual server instances that are created as needed, then terminated when the task is complete.
Why distribute a system?
Systems are always distributed by necessity. The truth of the matter is — managing distributed systems is a complex topic chock-full of pitfalls and landmines. It is a headache to deploy, maintain and debug distributed systems, so why go there at all? What a distributed system enables you to do is scale horizontally. Going back to our previous example of the single database server, the only way to handle more traffic would be to upgrade the hardware the database is running on. This is called scaling vertically.
Scaling vertically is all well and good while you can, but after a certain point you will see that even the best hardware is not sufficient for enough traffic, not to mention impractical to host.
Scaling horizontally simply means adding more computers rather than upgrading the hardware of a single one.
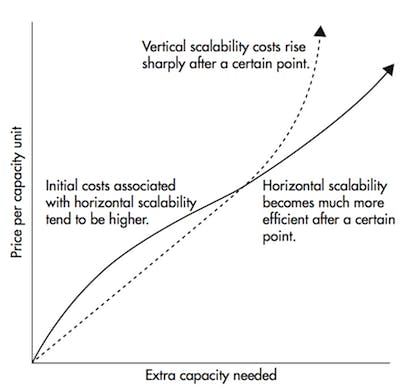
It is significantly cheaper than vertical scaling after a certain threshold but that is not its main case for preference.
Vertical scaling can only bump your performance up to the latest hardware’s capabilities. These capabilities prove to be insufficient for technological companies with moderate to big workloads. The best thing about horizontal scaling is that you have no cap on how much you can scale whenever performance degrades you simply add another machine, up to infinity potentially. Easy scaling is not the only benefit you get from distributed systems. Fault tolerance and low latency are also equally as important.
Fault Tolerance - a cluster of ten machines across two data centers is inherently more fault-tolerant than a single machine. Even if one data center catches on fire, your application would still work.
An important part of distributed systems is the CAP theorem, which states that a distributed data store cannot simultaneously be consistent, available, and partition tolerant.
Low Latency — The time for a network packet to travel the world is physically bounded by the speed of light. For example, the shortest possible time for a request‘s round-trip time (that is, go back and forth) in a fiber-optic cable between New York to Sydney is 160ms. Distributed systems allow you to have a node in both cities, allowing traffic to hit the node that is closest to it.
For a distributed system to work, though, you need the software running on those machines to be specifically designed for running on multiple computers at the same time and handling the problems that come along with it. This turns out to be no easy feat.
Key Characteristics of Distributed Systems
Scalability
Scalability is the capability of a system, process, or network to grow and manage increased demand. Any distributed system that can continuously evolve to support the growing amount of work is considered scalable.
A system may have to scale because of many reasons like increased data volume or increased work, e.g., number of transactions. A scalable system would like to achieve this scaling without performance loss.
Generally, although designed (or claimed) to be scalable, the performance of a system declines with the system size due to the management or environmental cost. For instance, network speed may become slower because machines tend to be far apart from one another. More generally, some tasks may not be distributed, either because of their inherent atomic nature or some flaw in the system design. At some point, such tasks would limit the speed-up obtained by distribution. A scalable architecture avoids this situation and attempts to balance the load on all the participating nodes evenly.
Horizontal vs. Vertical Scaling Horizontal scaling means that you scale by adding more servers into your pool of resources, whereas Vertical scaling means that you scale by adding more power (CPU, RAM, Storage, etc.) to an existing server.
With horizontal scaling, it is often easier to scale dynamically by adding more machines into the existing pool; Vertical-scaling is usually limited to the capacity of a single server. Scaling beyond that capacity often involves downtime and comes with an upper limit. Good examples of horizontal scaling are Cassandra and MongoDB, as they both provide an easy way to scale horizontally by adding more machines to meet growing needs. Similarly, a good example of vertical scaling is MySQL, as it allows for an easy way to scale vertically by switching from small to bigger machines. However, this process often involves downtime.
Reliability
By definition, reliability is the probability a system will fail in a given period. In simple terms, a distributed system is considered reliable if it keeps delivering its services even when one or several of its software or hardware components fail. Thus, reliability represents one of the main characteristics of any distributed system. Any failing machine can always be replaced by another healthy one in such systems, ensuring the completion of the requested task.
Take the example of a large electronic commerce store (like Amazon), where one of the primary requirements is that any user transaction should never be canceled due to a failure of the machine running that transaction. For instance, if a user has added an item to their shopping cart, the system is expected not to lose it. A reliable distributed system achieves this through the redundancy of both the software components and data. If the server carrying the user’s shopping cart fails, another server with the replica of the shopping cart should replace it. Redundancy has a cost, and a reliable system has to pay to achieve such resilience for services by eliminating every single point of failure.
Availability
By definition, availability is when a system remains operational to perform its required function in a specific period. It is a simple measure of the percentage of time that a system, service, or machine remains operational under normal conditions. For example, an aircraft that can be flown for many hours a month without much downtime has high availability. Availability takes into account maintainability, repair time, spares availability, and other logistics considerations. If an aircraft is down for maintenance, it is considered not available during that time.
Reliability is availability over time, considering the full range of possible real-world conditions that can occur. For example, an aircraft that can make it through any possible weather safely is more reliable than one that has vulnerabilities to possible conditions.
Reliability Vs. Availability
If a system is reliable, it is available. However, if it is available, it is not necessarily reliable. In other words, high reliability contributes to high availability. Still, it is possible to achieve a high availability even with an unreliable product by minimizing repair time and ensuring that spares are always available when they are needed.
Let’s take the example of an online retail store with 99.99% availability for the first two years after its launch. However, the system was launched without any information security testing. The customers were happy with the system, but they don’t realize that it isn’t very reliable as it is vulnerable to likely risks. In the third year, the system experiences a series of information security incidents that suddenly result in extremely low availability for extended periods. This results in reputational and financial damage to the customers.
Efficiency
To understand how to measure the efficiency of a distributed system, let’s assume an operation that runs in a distributed manner and delivers a set of items as a result.
Two standard measures of its efficiency are the response time (or latency) that denotes the delay to obtain the first item, and the throughput (or bandwidth), which denotes the number of items delivered in a given time unit (e.g., a second). The two measures correspond to the following unit costs:
The number of messages globally sent by the nodes of the system, regardless of the message size.
Size of messages representing the volume of data exchanges.
The complexity of operations supported by distributed data structures (e.g., searching for a specific key in a distributed index) can be characterized as a function of one of these cost units. Generally speaking, the analysis of a distributed structure in terms of the ‘number of messages’ is over-simplistic. It ignores the impact of many aspects, including the network topology, the network load, variation, the possible heterogeneity of the software and hardware components involved in data processing and routing, etc. However, it is quite difficult to develop a precise cost model that would accurately consider all these performance factors. Therefore, we’ve to live with rough but robust estimates of the system behavior.
Serviceability or Manageability
Another important consideration while designing a distributed system is how easy it is to operate and maintain. Serviceability or manageability is the simplicity and speed with which a system can be repaired or maintained
If the time to fix a failed system increases, then availability will decrease. Things to consider for manageability are the ease of diagnosing and understanding problems when they occur, ease of making updates or modifications, and how simple the system is to operate (i.e., does it routinely operate without failure or exceptions?).
Early detection of faults can decrease or avoid system downtime. For example, some enterprise systems can automatically call a service center (without human intervention) when the system experiences a system fault.
Challenges of distributed systems
Distributed systems are considerably more complex than monolithic computing environments, and raise a number of challenges around design, operations and maintenance. These include:
Increased opportunities for failure: The more systems added to a computing environment, the more opportunity there is for failure. If a system is not carefully designed and a single node crashes, the entire system can go down. While distributed systems are designed to be fault tolerant, that fault tolerance isn’t automatic or foolproof.
Synchronization process challenges: Distributed systems work without a global clock, requiring careful programming to ensure that processes are properly synchronized to avoid transmission delays that result in errors and data corruption. In a complex system — such as a multiplayer video game — synchronization can be challenging, especially on a public network that carries data traffic.
Imperfect scalability: Doubling the number of nodes in a distributed system doesn’t necessarily double performance. Architecting an effective distributed system that maximizes scalability is a complex undertaking that needs to take into account load balancing, bandwidth management and other issues.
More complex security: Managing a large number of nodes in a heterogeneous or globally distributed environment creates numerous security challenges. A single weak link in a file system or larger distributed system network can expose the entire system to attack.
Increased complexity: Distributed systems are more complex to design, manage and understand than traditional computing environments.
Risks of distributed systems
The challenges of distributed systems as outlined above create a number of correlating risks. These include:
Security: Distributed systems are as vulnerable to attack as any other system, but their distributed nature creates a much larger attack surface that exposes organizations to threats.
Risk of network failure: Distributed systems are beholden to public networks in order to transmit and receive data. If one segment of the internet becomes unavailable or overloaded, distributed system performance may decline.
Governance and control issues: Distributed systems lack the governability of monolithic, single-server-based systems, creating auditing and adherence issues around global privacy laws such as GDPR. Globally distributed environments can impose barriers to providing certain levels of assurance and impair visibility into where data resides.
Cost control: Unlike centralized systems, the scalability of distributed systems allows administrators to easily add additional capacity as needed, which can also increase costs. Pricing for cloud-based distributed computing systems are based on usage (such as the number of memory resources and CPU power consumed over time). If demand suddenly spikes, organizations.
Distributed System Architecture
Distributed systems must have a network that connects all components (machines, hardware, or software) together so they can transfer messages to communicate with each other.
That network could be connected with an IP address or use cables or even on a circuit board.
The messages passed between machines contain forms of data that the systems want to share like databases, objects, and files.
The way the messages are communicated reliably whether it’s sent, received, acknowledged or how a node retries on failure is an important feature of a distributed system.
Distributed systems were created out of necessity as services and applications needed to scale and new machines needed to be added and managed. In the design of distributed systems, the major trade-off to consider is complexity vs performance.
Types of Distributed System Architectures:
Distributed applications and processes typically use one of four architecture types below:
Client-server: In the early days, distributed systems architecture consisted of a server as a shared resource like a printer, database, or a web server. It had multiple clients (for example, users behind computers) that decide when to use the shared resource, how to use and display it, change data, and send it back to the server. Code repositories like git is a good example where the intelligence is placed on the developers committing the changes to the code.
Today, distributed systems architecture has evolved with web applications into:
Three-tier: In this architecture, the clients no longer need to be intelligent and can rely on a middle tier to do the processing and decision making. Most of the first web applications fall under this category. The middle tier could be called an agent that receives requests from clients, that could be stateless, processes the data and then forwards it on to the servers.
Multi-tier: Enterprise web services first created n-tier or multi-tier systems architectures. This popularized the application servers that contain the business logic and interacts both with the data tiers and presentation tiers.
Peer-to-peer: There are no centralized or special machine that does the heavy lifting and intelligent work in this architecture. All the decision making and responsibilities are split up amongst the machines involved and each could take on client or server roles. Blockchain is a good example of this.
Distributed Data Stores
Distributed Data Stores are most widely used and recognized as Distributed Databases. Most distributed databases are NoSQL non-relational databases, limited to key-value semantics. They provide incredible performance and scalability at the cost of consistency or availability.
We cannot go into discussions of distributed data stores without first introducing the CAP Theorem.
CAP Theorem The CAP theorem states that a distributed data store cannot simultaneously be consistent, available and partition tolerant.
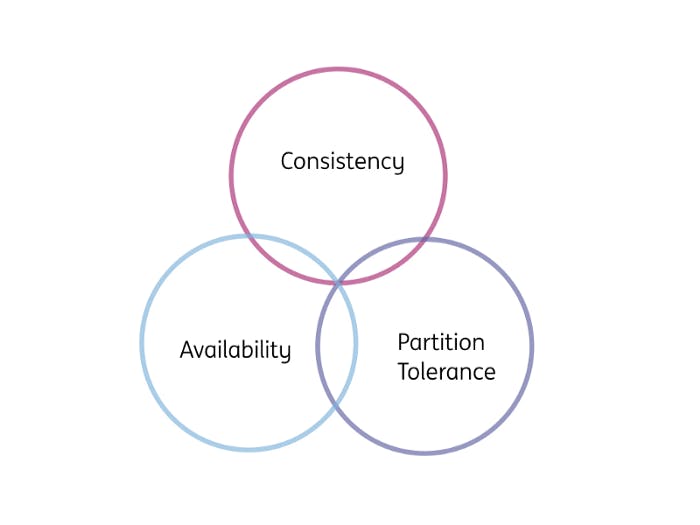
Some quick definitions:
Consistency — What you read and write sequentially is what is expected
Availability — the whole system does not die — every non-failing node always returns a response.
Partition Tolerant — The system continues to function and uphold its consistency/availability guarantees in spite of network partitions
In reality, partition tolerance must be a given for any distributed data store. As mentioned in many places, one of which this great article, you cannot have consistency and availability without partition tolerance.
Think about it: if you have two nodes which accept information and their connection dies — how are they both going to be available and simultaneously provide you with consistency? They have no way of knowing what the other node is doing and as such have can either become offline (unavailable) or work with stale information (inconsistent).
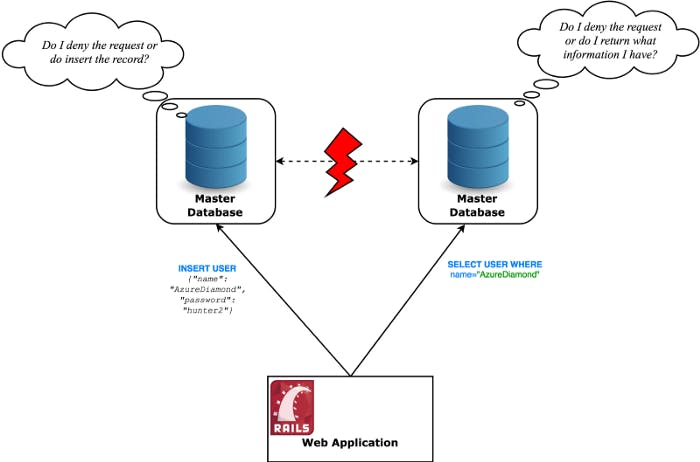
In the end you’re left to choose if you want your system to be strongly consistent or highly available under a network partition.
Practice shows that most applications value availability more. You do not necessarily always need strong consistency. Even then, that trade-off is not necessarily made because you need the 100% availability guarantee, but rather because network latency can be an issue when having to synchronize machines to achieve strong consistency. These and more factors make applications typically opt for solutions which offer high availability.
Such databases settle with the weakest consistency model — eventual consistency (strong vs eventual consistency explanation). This model guarantees that if no new updates are made to a given item, eventually all accesses to that item will return the latest updated value.
Those systems provide BASE properties (as opposed to traditional databases’ ACID)
- Basically Available — The system always returns a response
- Soft state — The system could change over time, even during times of no input (due to eventual consistency)
- Eventual consistency — In the absence of input, the data will spread to every node sooner or later — thus becoming consistent
Examples of such available distributed databases — Cassandra, Riak, Voldemort
Of course, there are other data stores which prefer stronger consistency — HBase, Couchbase, Redis, Zookeeper
The CAP theorem is worthy of multiple articles on its own — some regarding how you can tweak a system’s CAP properties depending on how the client behaves and others on how it is not understood properly.
Cassandra
Cassandra, as mentioned above, is a distributed No-SQL database which prefers the AP properties out of the CAP, settling with eventual consistency. I must admit this may be a bit misleading, as Cassandra is highly configurable — you can make it provide strong consistency at the expense of availability as well, but that is not its common use case.
Cassandra uses consistent hashing to determine which nodes out of your cluster must manage the data you are passing in. You set a replication factor, which basically states to how many nodes you want to replicate your data.
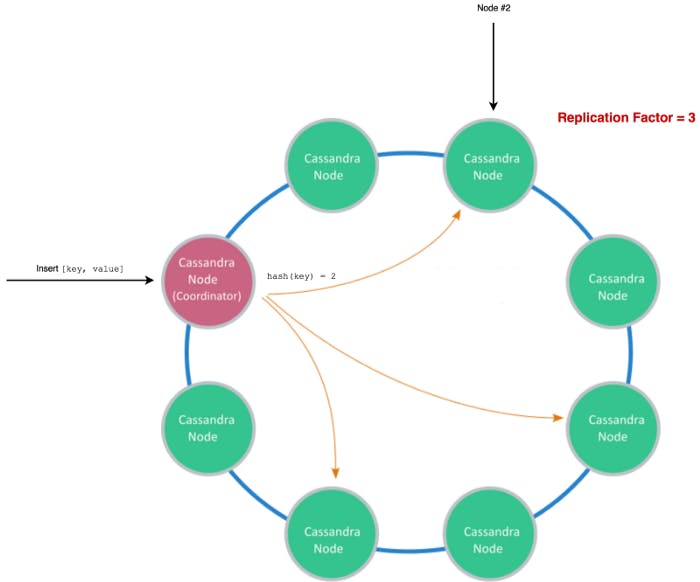
When reading, you will read from those nodes only.
Cassandra is massively scalable, providing absurdly high write throughput.
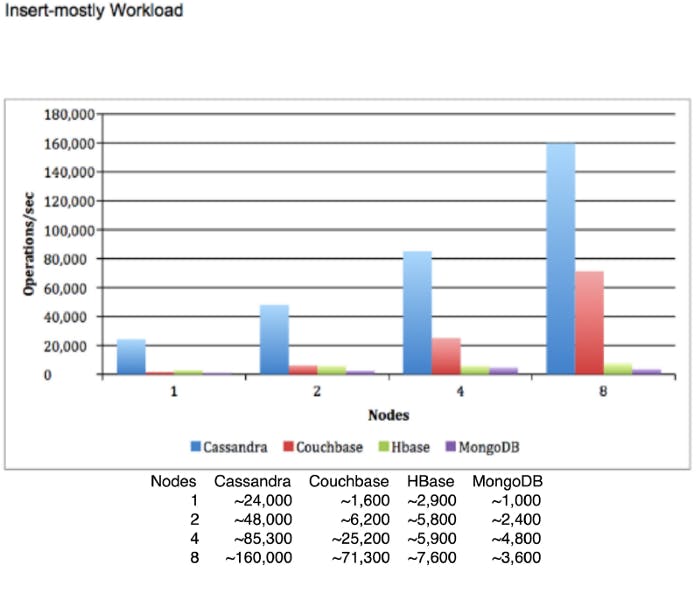
Even though this diagram might be biased and it looks like it compares Cassandra to databases set to provide strong consistency (otherwise I can’t see why MongoDB would drop performance when upgraded from 4 to 8 nodes), this should still show what a properly set up Cassandra cluster is capable of.
Regardless, in the distributed systems trade-off which enables horizontal scaling and incredibly high throughput, Cassandra does not provide some fundamental features of ACID databases — namely, transactions.
Distributed Messaging
Messaging systems provide a central place for storage and propagation of messages/events inside your overall system. They allow you to decouple your application logic from directly talking with your other systems.
Known Scale — LinkedIn’s Kafka cluster processed 1 trillion messages a day with peaks of 4.5 millions messages a second.
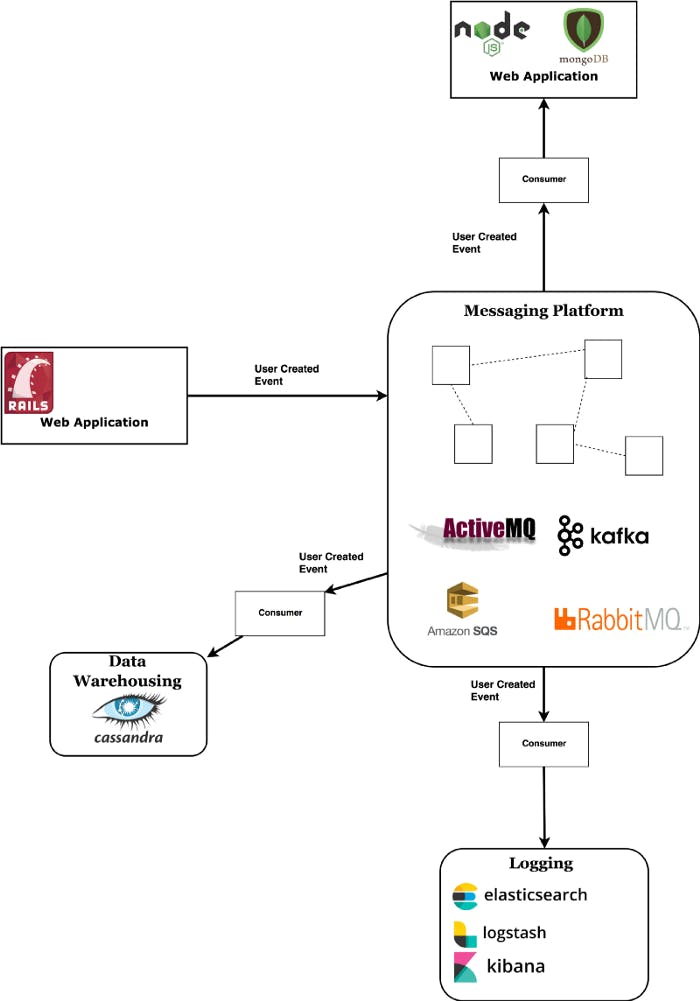
Simply put, a messaging platform works in the following way: A message is broadcast from the application which potentially create it (called a producer), goes into the platform and is read by potentially multiple applications which are interested in it (called consumers).
If you need to save a certain event to a few places (e.g user creation to database, warehouse, email sending service and whatever else you can come up with) a messaging platform is the cleanest way to spread that message.
Consumers can either pull information out of the brokers (pull model) or have the brokers push information directly into the consumers (push model).
There are a couple of popular top-notch messaging platforms: RabbitMQ — Message broker which allows you finer-grained control of message trajectories via routing rules and other easily configurable settings. Can be called a smart broker, as it has a lot of logic in it and tightly keeps track of messages that pass through it. Provides settings for both AP and CP from CAP. Uses a push model for notifying the consumers.
Kafka — Message broker (and all out platform) which is a bit lower level, as in it does not keep track of which messages have been read and does not allow for complex routing logic. This helps it achieve amazing performance. In my opinion, this is the biggest prospect in this space with active development from the open-source community and support from the Confluent team. Kafka arguably has the most widespread use from top tech companies. I wrote a thorough introduction to this, where I go into detail about all of its goodness.
Apache ActiveMQ — The oldest of the bunch, dating from 2004. Uses the JMS API, meaning it is geared towards Java EE applications. It got rewritten as ActiveMQ Artemis, which provides outstanding performance on par with Kafka.
Amazon SQS — A messaging service provided by AWS. Lets you quickly integrate it with existing applications and eliminates the need to handle your own infrastructure, which might be a big benefit, as systems like Kafka are notoriously tricky to set up. Amazon also offers two similar services — SNS and MQ, the latter of which is basically ActiveMQ but managed by Amazon.
Data Copying
Copying is another foundational concept in computing. In software design we use the concept of taking data copies to achieve speed and resilience in several different ways.
Replicas A data replica is an exact copy of a database. Replicas are constantly, iteratively synced with one another so their contents are kept as identical as possible. They generally come in two flavours, active and passive. Active replicas support read and write access and play an (unsurprisingly) active role in serving clients. Active replicas can help with scale, resilience and location-base performance. Passive replicas are generally maintained for failover purposes; they don’t support read or write and are only synced in one direction (from the master data). The job of a passive replica is to be ready to take over from the main replica if it fails.
Caches Unlike a replica, a cache is a not-necessarily-identical, read-only, copy of your data, usually maintained as a way to serve read requests faster and more cheaply than querying your main database. Caches may take advantage of
Location (keeping information physically close to the reading client).
Medium (keeping information in faster-to-access physical media like memory rather than disk).
Design (maintaining information in data structures optimised for fast read like key/value stores or graphs).
Backups A backup is a copy of your data for emergency use in the case of catastrophic data loss. Usually a backup is written to a permanent storage medium like disk in multiple physical locations. Backups are slow to write to and restore from and usually they are not kept constantly in sync with the master data. Instead, they are periodically updated. They are useful but have severe limitations and can easily lull folk into a false sense of security. This false security becomes especially dangerous as the scale and complexity of a system increases.
Denormalization for Decoupling Data duplication goes in and out of fashion as an architectural technique. It is often frowned upon because it’s a common cause of bugs. On the other hand, it is very useful for performance. Basically, like everything in life it has pros and cons and we need to make a judgment on whether to use it based on the current circumstances.
A decade ago we spent ages “normalizing” our databases, or removing data duplication. However in a distributed system we really need to have data available in more than one location. Every service cannot be calling back to the same database all the time or we lose all the benefits of distribution. Microservices usually maintain local equivalents of certain pieces of data that they can write and read without worrying about anyone else.
BUT the potential bugs have not mysteriously gone away. We have to somehow keep all those data copies in alignment (that doesn’t necessarily mean identical). By using data duplication we have to accept that we’ve just included an architectural technique that can be very bug prone in our design. It’s a tradeoff. It just means that we have to use development techniques that help resolve those problems such as Domain Driven Design, or operational techniques like managed stateful services that handle some of these issues for us.
Decentralized vs Distributed Before we go any further I’d like to make a distinction between the two terms.
Even though the words sound similar and can be concluded to mean the same logically, their difference makes a significant technological and political impact.
Decentralized is still distributed in the technical sense, but the whole decentralized systems is not owned by one actor. No one company can own a decentralized system, otherwise it wouldn’t be decentralized anymore.
This means that most systems we will go over today can be thought of as distributed centralized systems — and that is what they’re made to be.
Decentralized is essentially distributed on a technical level, but usually a decentralized system is not owned by a single source.
If you think about it — it is harder to create a decentralized system because then you need to handle the case where some of the participants are malicious. This is not the case with normal distributed systems, as you know you own all the nodes.
This has been debated a lot and can be confused with others (peer-to-peer, federated). In early literature, it’s been defined differently as well. Regardless, what I gave you as a definition is what I feel is the most widely used now that blockchain and cryptocurrencies popularized the term.
Cloud vs distributed systems Cloud computing and distributed systems are different, but they use similar concepts. Distributed computing uses distributed systems by spreading tasks across many machines. Cloud computing, on the other hand, uses network hosted servers for storage, process, data management.
Distributed computing aims to create collaborative resource sharing and provide size and geographical scalability. Cloud computing is about delivering an on demand environment using transparency, monitoring, and security.
Compared to distributed systems, cloud computing offers the following advantages:
Cost effective
Access to a global market
Encapsulated change management
Access storage, servers, and databases on the internet
However, cloud computing is arguably less flexible than distributed computing, as you rely on other services and technologies to build a system. This gives you less control overall.
Priorities like load-balancing, replication, auto-scaling, and automated back-ups can be made easy with cloud computing. Cloud building tools like Docker, Amazon Web Services (AWS), Google Cloud Services, or Azure make it possible to create such systems quickly, and many teams opt to build distributed systems alongside these technologies.